
This reading is divided into seven main sections. Section 2 covers ‘What is Fintech?’ Sections 3 and 4 cover ‘Big data’, ‘artificial intelligence’, and ‘machine learning’. Section 5 covers data science. Section 6 covers applications of fintech to investment management. Finally, section 7 covers distributed ledger technology.
The term ‘Fintech’ comes from combining ‘Finance’ and ‘Technology’. Fintech refers to technological innovation in the design and delivery of financial products and services.
Though the term ‘Fintech’ is relatively new, its earlier forms involved data processing and automation. Fintech’s recent advancement include developing several decision-making applications.
The major drivers of fintech have been:
While Fintech spans the entire finance space, this reading focuses on fintech applications in the investment management industry. The major applications are:
Big Data refers to vast amount of data generated by industry, governments, individuals, and electronic devices. Characteristics of big data typically include:
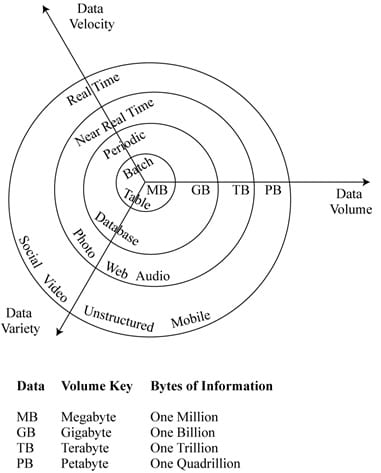
Traditional data sources include annual reports, regulatory filings, trade price and volume, etc. Alternate data include many other sources and types of data. A simple classification of alternate data sources is shown in Exhibit 2 of the curriculum.
| Individuals | Business Processes | Sensors |
| Social media | Transaction data | Satellites |
| News, reviews | Corporate data | Geolocation |
| Web searches, personal data | Internet of Things | |
| Other sensors |
While big data can be a huge asset, there are also several challenges. The quality of data may be questionable. The data may have biases, outliers, etc. The volume of data collected may not be sufficient. We might be dealing with too much data or too little data. Another concern is the appropriateness of data. In most cases working with Big Data usually involves cleansing and organizing the data before we start analyzing it.
Artificial intelligence (AI) computer systems perform tasks that have traditionally required human intelligence. They exhibit cognitive and decision-making ability comparable or superior to that of human beings. An important term in this context is ‘neural networks’. It refers to programming based on how the brain learns and processes information. There are examples of AI all around us. For example, chess playing computer programs, digital assistants like Apple’s Siri, etc.
Machine learning (ML) refers to computer-based techniques that “extract knowledge from large amounts of data by “learning” from known examples and then generating structure or predictions” without relying on any help from a human. ML algorithms aim to “find the pattern, apply the pattern.”
In ML, the dataset is divided into three distinct subsets:
Once an algorithm has mastered the training and validation datasets, it can be used to predict outcomes based on other datasets.
Broadly speaking there are three main approaches to machine learning:
Deep learning: In deep learning, (or deep learning nets), neural networks are used by the computers to perform multistage, non-linear data processing to identify patterns. Deep learning can use supervised or unsupervised machine learning approaches. With terms like AI and ML one might think that human judgment is not required, but that is far from the truth. For ML to work well, good human judgment is required. Human judgment is required for questions like: which data to use, how much data to use, which analytical techniques are relevant in the given context. Human judgment may also be needed to clean and filter the data before it is fed to the ML algorithm.
Some challenges associated with machine learning are:
Despite these challenges and weaknesses, the importance of ML in finance and investment management has been growing substantially. In the next few sections, we will look at specific applications of AI and ML in the context of investment management.
Data science leverages advances in computer science, statistics, and other disciplines for the purpose of extracting information from Big Data.
Data processing methods include:
Another aspect of data science is data visualization. This refers to how the data will ultimately be presented to the analyst/user. Historically, data visualization happened through graphs, charts, etc. However, in more recent times tools such as heat maps, tree diagrams, and tag clouds are also being used.
An example of a heat map is a map of a city where routes with high traffic congestion are shown in red. A tag cloud is a technique applicable to textual data. Words that appear more often are shown in a larger font, whereas words that appear less often are shown with a smaller font. This helps us to quickly evaluate how consumers/users are talking about a given product.




Ace the Exam with Active Learning!

Ace the Exam with IFT Notes!
 Do IFT Mocks to make you exam-ready!
Do IFT Mocks to make you exam-ready!

Accelerate your studies!

Practice your way to success!


Sign up to get more!